背景
近年,災害現場の探索や宇宙空間での活動など,事前の環境予測が困難な領域において,各機の問題に対する頑健さや,システム規模変更の容易さ,柔軟なシステムの変化による環境変化への適応という特性から,自律分散型マルチエージェントシステム(MAS)の応用が期待されている. しかし,多くの先行研究では,全エージェントの探索履歴を共有するなど広域情報に依存しており,通信インフラに乏しい環境下での運用における課題があったほか,時間経過に伴う風向変化などの,不規則かつ動的な環境変化への適応能力についての検証が十分ではなかった. 本研究では,局所情報のみを用いた強化学習ベースの制御手法により,不規則かつ動的な環境変化に対する適応能力と有効性を検証することを目的とし,不規則変化をもつ環境のシミュレーションと,制御アルゴリズムの設計を行った.
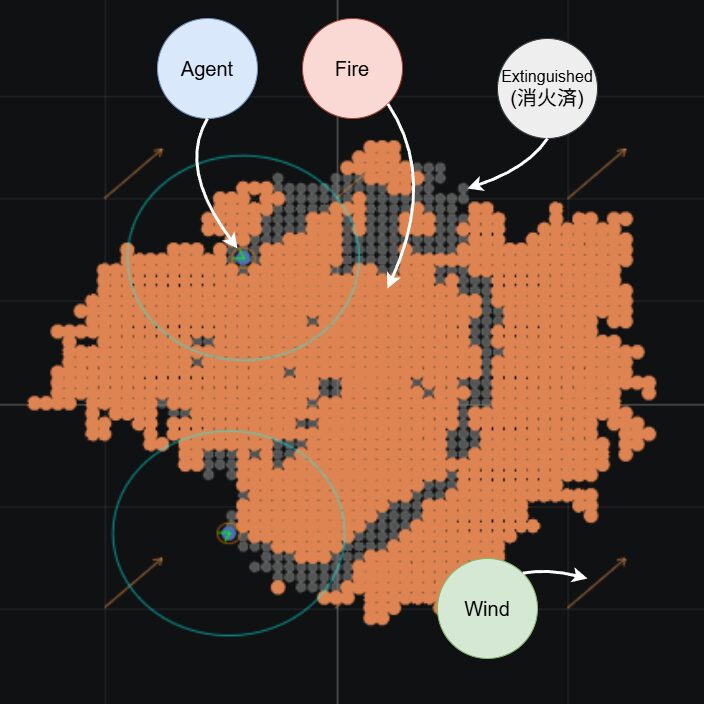
提案手法
不規則変化をもつ環境シミュレーション
検証環境として,セル・オートマトンを基礎とした森林火災シミュレーションを構築した.隣接セル間で非現実的な変化を排しつつ,動的かつ不規則な延焼拡大を再現するため,Perlin Noiseを用いて時間的・空間的に連続して変化する風を生成し,これを延焼確率に反映させた.
エージェント制御アルゴリズム
局所情報のみでの環境適応能力を比較検証するため,以下の2つの手法を設計した.
・強化学習ベース手法: Deep Q-Networkを用い,エージェントの認識可能半径内の情報(自己速度,近傍エージェント位置,火炎密度など)のみを入力として行動を決定する.報酬には,消火成功,火炎接近,他機接触ペナルティなどを設定し,自律的な行動則の獲得を目指した.
・ルールベース手法: 比較対象として,群知能の基本的なモデルであるBoids(分離・整列・結合)に対し,火炎発見時の「目標誘引力」と,未発見時の「ランダムウォーク探索力」を追加したアルゴリズムを実装した.
実験結果
100×100セルのフィールド外縁にエージェント5機をランダムに配置し,火炎数が0(成功),または2500(失敗)に到達するまでを1エピソードとしてシミュレーションを行い,2手法を比較した.
その結果,ルールベース手法での消火成功率がわずか2%であったのに対し,学習が進んだ段階(101-150エピソード)の強化学習ベース手法は94%の成功率を達成した.また,火炎セル数の推移において,強化学習ベース手法は特にタスク初期(〜700ステップ)で優れた延焼抑制効果を示した.これは,エージェントが衝突を回避しながら効率的に分散し,初期消火を行う行動則を獲得したためと考えられる.
結論
本研究により,局所情報のみを用いての強化学習によるMASは,不規則な環境変化に対し,ルールベース手法を大きく上回る適応能力を持つことが確認された. 一方,タスクが長期化した場面においては,機数不足などシステム全体の物理的な処理能力による限界も見られた. 今後の展望として,エージェント数の増加によるスケーラビリティの検証や,通信へのノイズなどを加味した,より厳しい制約下におけるロバスト性の向上が挙げられる.