概要
多数ロボット(マルチエージェントシステム)は冗長性と分散性によりロバストに振る舞えるため,災害現場・屋内探索・海底探査など実環境での応用が期待される。
一方で実環境では,通信インフラの崩壊,遮蔽,反射,混雑などにより通信が断続的になりやすく,全体俯瞰に依存した集中制御は破綻しやすい.
本研究は,局所観測・局所通信のみを前提として,Target(発見対象)情報をBase(基地局)へ集約する課題を扱い,マルチホップ中継を活用した情報到達時間の短縮を目指す.
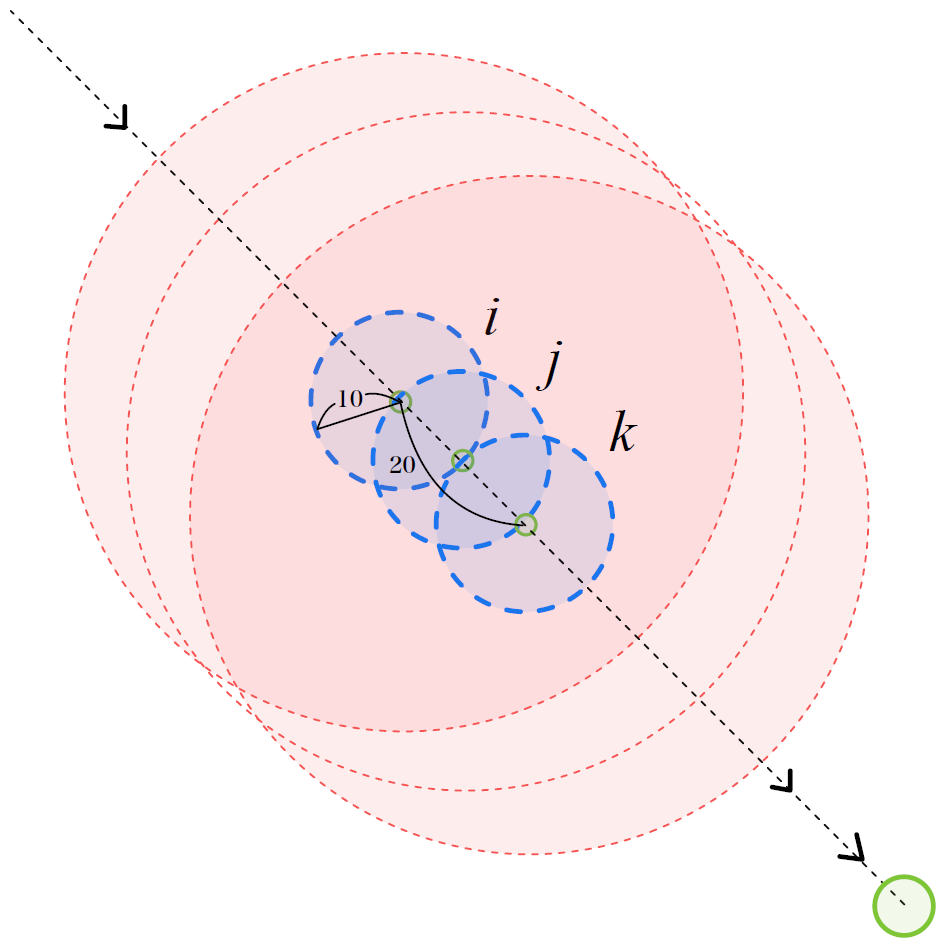
局所通信制約下におけるマルチホップ情報伝達の空間的イメージ
直感的イメージ
本課題は「見つけた情報をバケツリレーで基地へ運ぶ問題」に近い.
ただし,各ロボットは近くしか見えず,近くとしか通信できない.
その場その場の局所判断だけで「誰が探索を続け,誰が中継として前へ送るか」を切り替える必要がある.
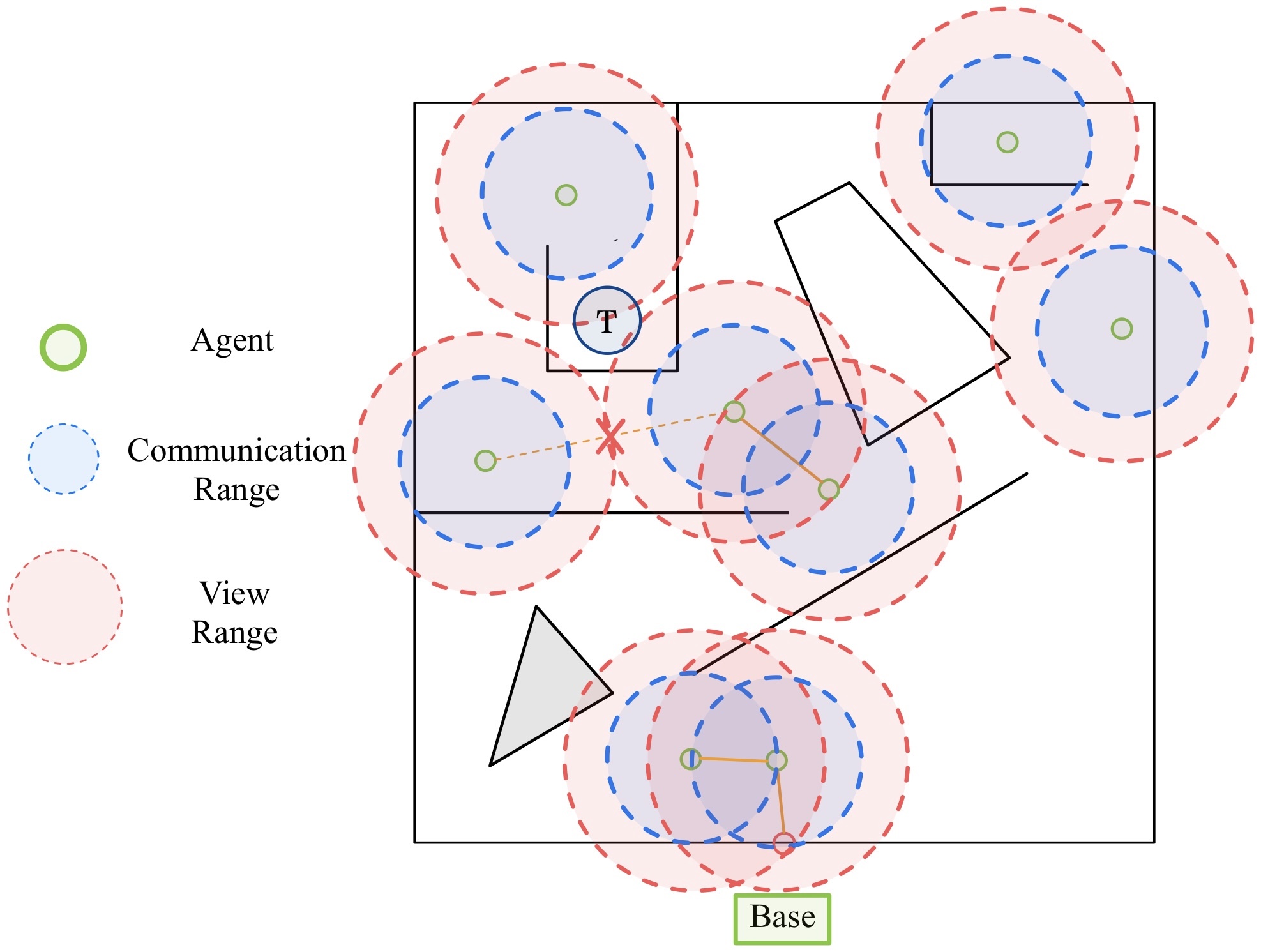
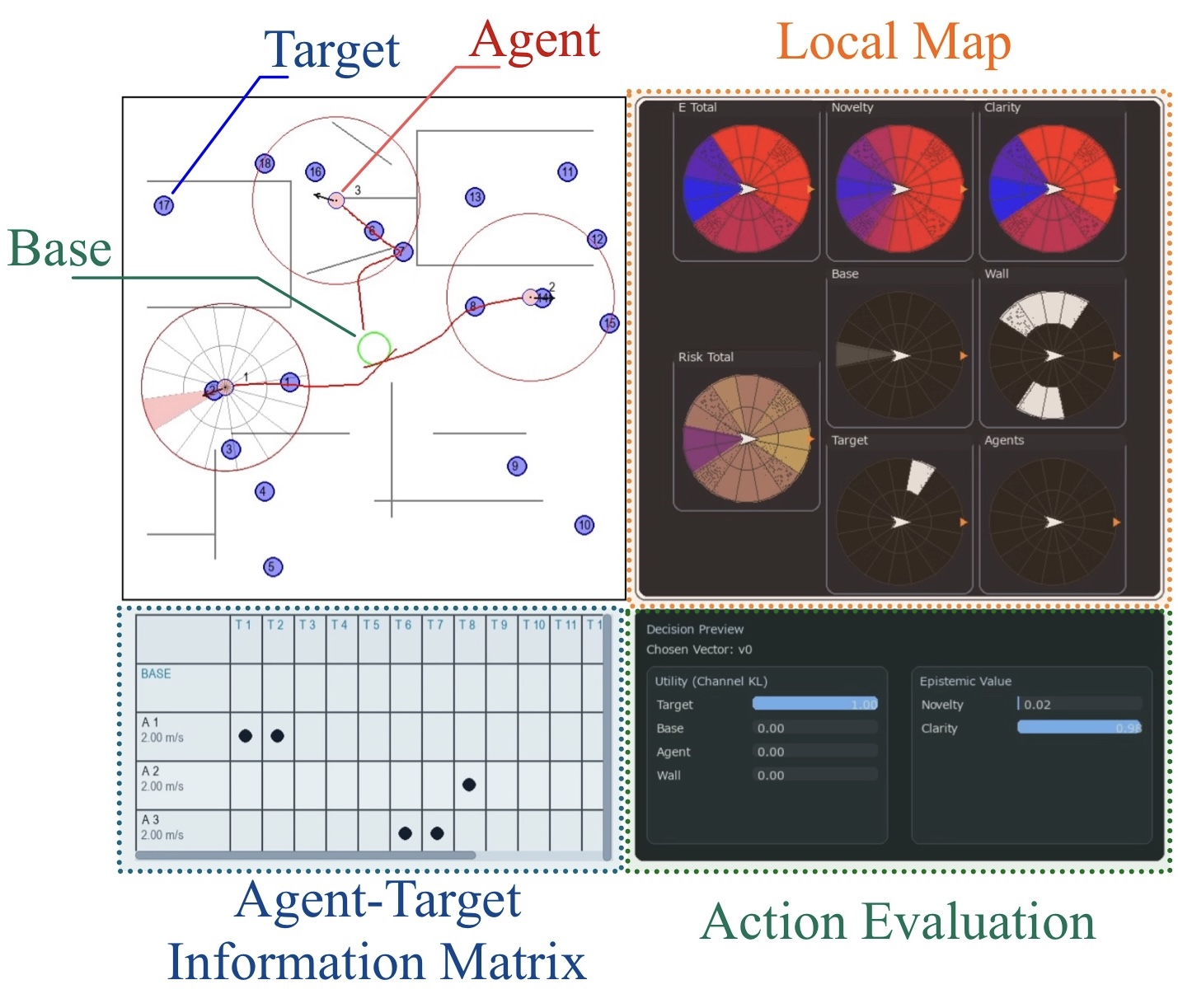
(左)評価タスク環境の模式図。各Agentは視野範囲(View Range)と局所通信範囲(Communication Range)に制約され,Target情報はマルチホップ中継によりBaseへ到達する.
(右)推論基盤型モデル(AI)の可視化例。極座標ローカルマップ(Target/Base/Agent/Wall各チャネル)と,行動候補に対する評価(リスク:選好分布とのKL,認識的価値:novelty/clarity)を表示.
研究目的
グローバル視点や中央集権制御に依存せず,局所観測・局所通信とマルチホップ中継のみで,探索と報告を同時に効率化する意思決定枠組みを確立する.
そのために,以下の2手法を設計・実装し,遮蔽・障害を含む環境で評価する.
- モデル①:相対角度評価型(RA)
遭遇時の局所幾何量(余弦類似度)から,「情報前方移譲(渡す)」と「先回り受け取り(受け取って運ぶ)」を判定し,マルチホップ伝達を促進する. - モデル②:推論基盤型(AI)
能動的推論に基づき,将来観測の予測分布と「こう見えてほしい」選好分布の整合を評価して行動を選択し,診断量(KL等)で応答特性を分析する..
モデル①:相対角度評価型(RA)――前へ送る/先回りするの局所幾何判断
RAは,遭遇した2台のロボット間で「情報を前へ送る(前方移譲)」か「受け取り側が先回りして運ぶ」かを,局所的な幾何量(余弦類似度)のみで評価し,Baseへの情報到達時間短縮を狙うモデルである.
各ロボットは,Target方向・Base方向・探索方向などの単位ベクトルを用い,それらの合成で移動を行う.
さらに通信範囲内で他ロボットに遭遇したとき,保持側は前方移譲の適合度を,受け取り側は先回り適合度をそれぞれ評価し,閾値判定によりマルチホップ伝達を構成する.
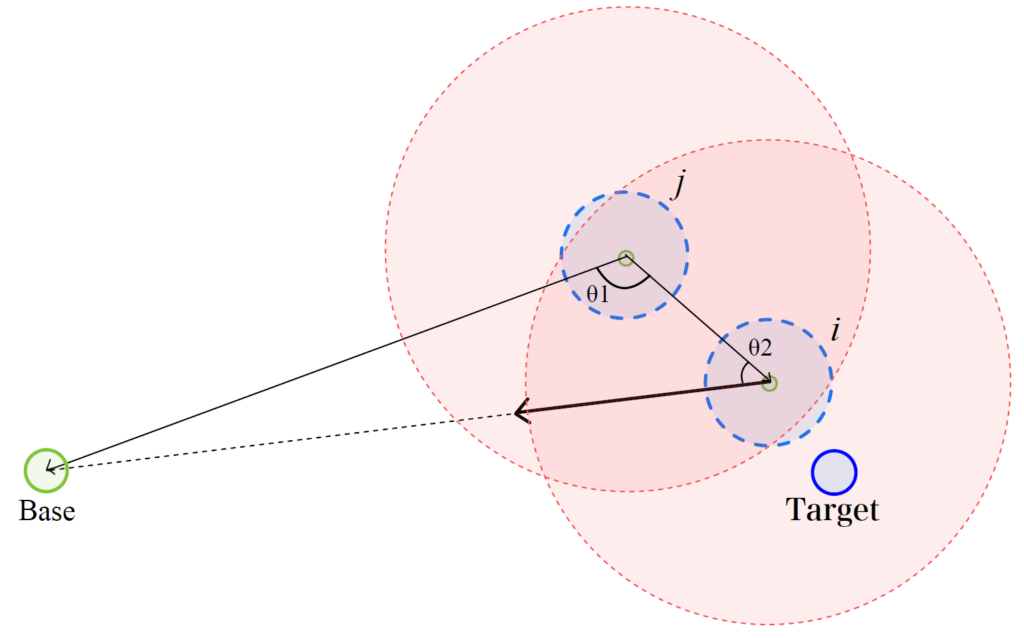
前方移譲と先回り判断の概念図
モデル①の結果(要点)
- 前方移譲ありモデルは,前方移譲なしモデルより完了時間が短くなる傾向を示し,遮蔽・内壁環境でも分布が短い側へシフトした.
- 速度を上げた参照条件と比較し,単純な高速化ではなく「局所中継判断」自体が効率化に寄与することを同一指標で切り分けて評価した.
- 先回り側の閾値は性能に影響しやすく,条件依存の特性が確認された(閾値設計が課題として残る).
モデル②:推論基盤型(AI)――望ましい見え方に基づく行動評価(能動的推論)
AIは,能動的推論の枠組みに基づき,ロボットが将来の見え方(将来観測分布)を予測し,「こう見えてほしい」という選好分布と整合するように行動を選ぶモデルである.
行動候補ごとに期待自由エネルギー(Expected Free Energy; EFE)を評価し,選好へ向かう実利(リスク)と,より良く知るための認識的価値(情報獲得)を統合する.
本研究では実装検証として,局所マップを極座標グリッド(4リング×16ビン)で量子化し,Agent/Target/Base/Wallのチャネル地図を用いた.
診断量として,Targetに対するリスク項(将来観測分布と選好分布の不一致をKLダイバージェンスで測る量)を時系列で解析し,選好に基づく応答を可視化した.
また,調査と中継の役割を合成し,重みの変化による挙動変化を観察した.
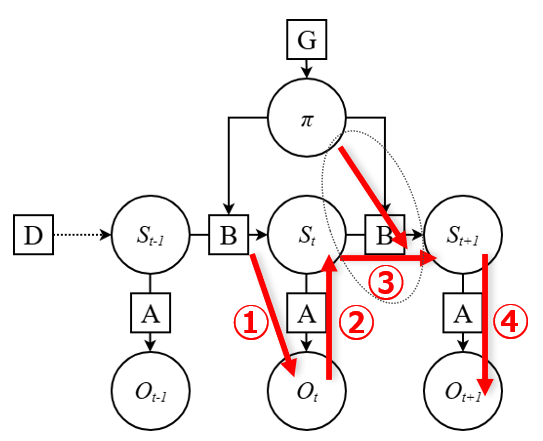
能動的推論に基づく意思決定の基本的な流れ
①現在の状態から観測を得て,②周囲の位置状態を更新し,③将来状態を予測して行動を選択し,④その行動により次の観測が生成される.
モデル②の結果(要点)
- Targetチャネルに選好を与えると,予測とEFE最小化によりTargetへ接近する挙動を確認した.
- Targetリスク項(KL)を診断量として取り出し,接近に伴うリスク低下を観察した.
- 役割合成(調査×中継)の重みにより挙動が変化し,枠組みが行動の方向づけとして機能することを確認した.
動作イメージ動画
Target情報を取得しようとする,Agentの動作.
本研究の意義
(1) 局所幾何量のみの単純な実装で,情報到達時間短縮に効く「前方移譲/先回り」の局所規則(RA)を提示した点に意義がある.
(2) 一方で,タスク依存閾値に頼りすぎない一般形として,選好分布から行動評価を構成する推論基盤(AI)を実装し,診断量(KL)で応答を評価した点に意義がある.
(3) 両者を「情報流の骨格(RA)」と「状況適応と配分最適化(AI)」として役割分担させる設計は,局所通信・部分観測という制約下で探索と報告のトレードオフを一貫して扱う上で有望である.
今後の展望
今後は,完了時間だけでなく運動負担・通信負担・負荷集中など複数指標を導入し,条件変化に対する性能維持や失敗境界を評価する.
また,AI側の評価量(リスク/認識的価値)とRA側の閾値(特に先回り側)を状況依存に更新できれば,環境ごとの再調整負担を軽減できる.
最終的には,局所で動ける強さを維持したまま,探索と報告の動的バランス調整を自律的に実現する分散設計へ拡張する.